在文本处理和数据挖掘领域有一种非常重要的方法,那就是主题模型方法。他能有效的从文本语义中提取主题信息。主题模型主要由词、文档和话题构成。其中文档是要处理的数据源,它由很多词构成。从文档中我们能抽取一些词的集合,最终构成一个个主题。凡是类似这种结构的模型(甚至不仅仅是文本模型),都可以使用主题模型方法。因此,这一种方法有其自身很强的普适性。在过去,尤其是在可视化领域,分析主题模型的工具往往是用来分析其有效性的,对于比较不同的主题模型来说,方法与工具是极其少见的。而这篇论文就是从主题模型的比较入手,通过多种可视化方法来更有效地对不同主题模型的结果进行比较。
对于比较主题模型的比较, 我们比较的不仅仅是方法,不同的方法,不同的主题个数选取,不同的参数,都能产生不同的结果,这些结果甚至可能差异巨大。因此,我们对主题模型的比较不仅仅应该比较不同方法,可能还需要比较不同的参数选取等。
这篇文章对于主题模型的比较,可以从三个方面入手:主题内容、主题相似性、主题时变。其中主题内容主要比较同一个文章不同方法得出的主题内容的差异。相似性比较主要是对使用不同方法导致的不同文章之间主题相似性差异做对比。而最后主题时变则是比较不同模型对于主题变化的影响。下面分别从这三个方面对论文的方法进行阐述。
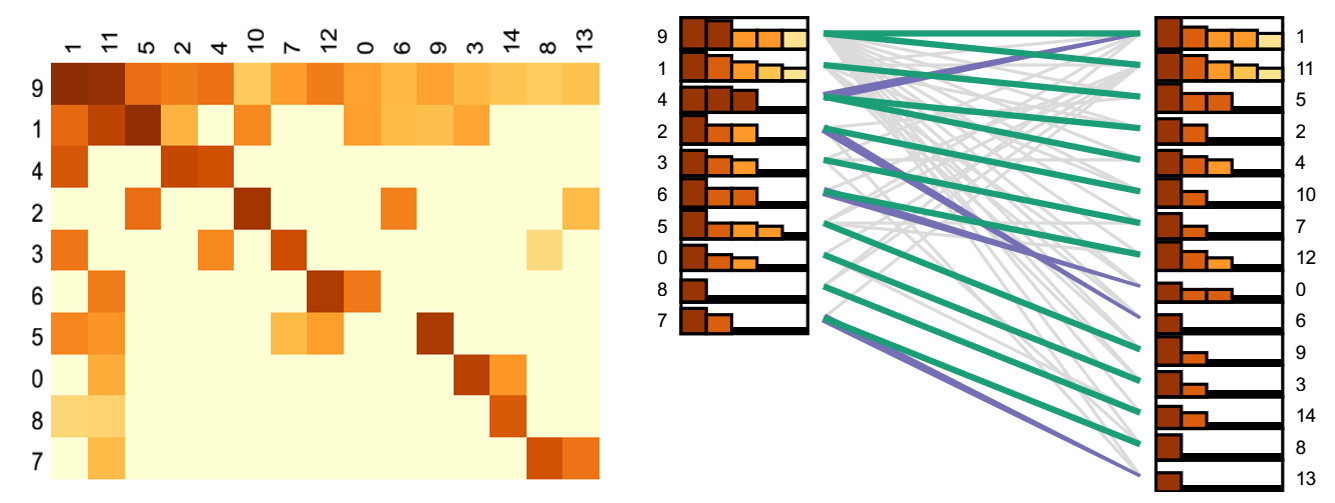
对于主题内容的方式,作者设计了两种可视化方法,这些方法主要用来比较不同方法得出的主题的匹配程度。图1上左部分的矩阵中,横轴和纵轴分别表示了两个不同的主题模型,其中一个包含10个主题,另一个包含15个主题,对应的方格的颜色表示了这两个主题的匹配程度。在这里主题的排列顺序作者采用了乱序排列,这种乱序是为了主题之间保证最强的联系在对角线上,从而方便用户比较主题的匹配程度。而图1 的右半部分用类似平行坐标图的形式表示了两个模型的主题之间的匹配程度。左右两边分别表示这两个模型,绿色连线表示对应的两个主题是互相匹配的,而紫色连线表示的是单向匹配。因此,通过分析这两个图我们可以看出两个模型中哪些主题是互相匹配的,哪些主题在另外一个模型中被合并或分裂了。对于两个方法来说,可以看到每个topic有5个柱状图,这些柱状图表示与另一个方法具有最强链接的前五个主题的相似性。
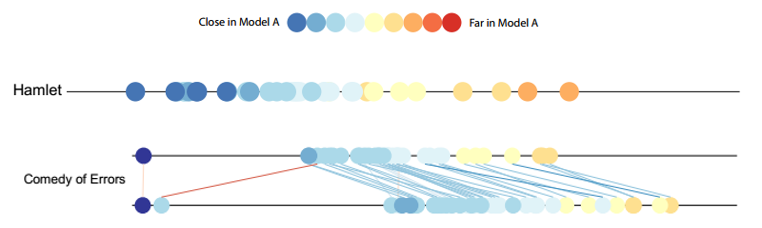
分析不同主题模型的相似性也是比较不同模型的一个切入点。对一个文档来说,文档与其他文档与它的距离是如何分布的呢?基于两种模型计算的距离之前差异有多大?在这里作者提出了一种buddy plots的可视化设计每个 buddy plots可以比较两种主题模型方法。buddy plots作者主要分为以下两种:
Single buddy plots:仅仅使用一个轴来用x值和颜色来编码相应的modal信息
Parallel buddy plots:除了使用x和颜色之外还采用了连线的方式展示出两种不同的buddy的关系
对于Single buddy plots而言,我们选取其中一篇文档,比较其他文档到这一篇文档的距离。其横轴从左到右每一个原点表示一个不同的文档,从左到右的x值表示使用方法A得出的不同文档间话题模型得出的topic到我们选取的基础文档之间的距离,原点的颜色则表示我们的方法B得出的不同文档到基础文档的距离,颜色越红表示距离越远。因此,在比较过程中如果从左到右颜色依次变红则说明两个方法得出的模型结论是相似的,而颜色排列越杂乱则说明两个方法越不匹配。
对于Parallel buddy plots而言,我们依旧选取其中一篇文档,比较其他文档到这一篇文档的距离。其第一条横轴从左到右每一个原点表示一个不同的文档,从左到右的x值表示使用方法A得出的不同文档间话题模型得出的topic到我们选取的基础文档之间的距离,原点的颜色则表示我们的方法A得出的不同文档到基础文档的距离,颜色越红表示距离越远。对于第二条轴,我们x值采用了方法B得出的文档距离,第一条线和第二条线之间用一条直线连接相同的文档,两个相同的文档在坐标轴上距离越远则线的颜色越红(前向距离)或者越蓝(后向距离),表示两种方法越不相似。
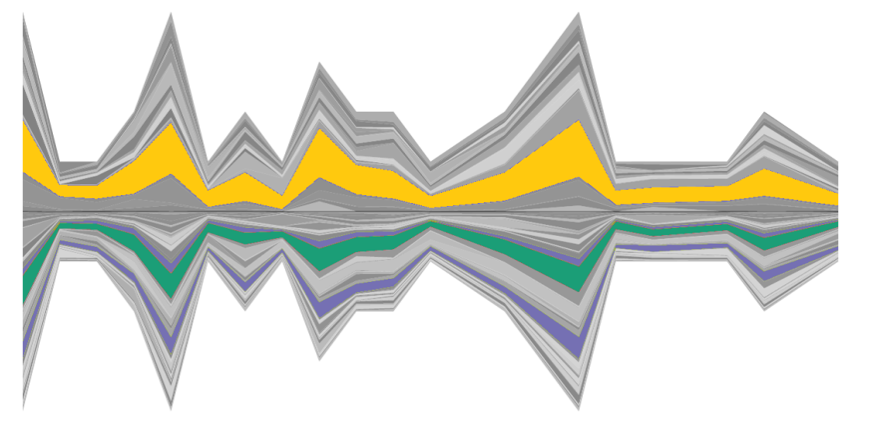
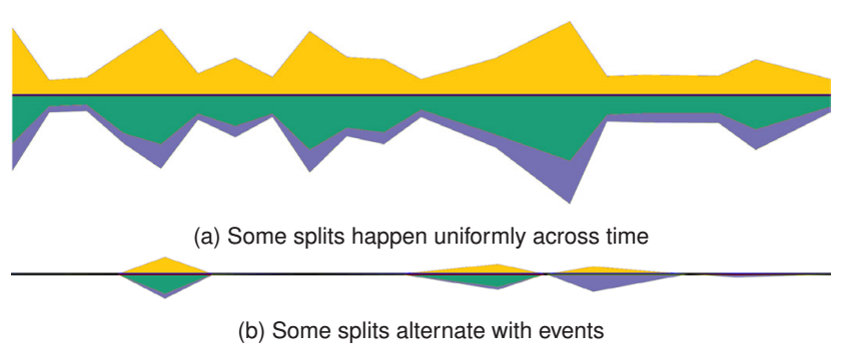
主题随时间的演变趋势也是比较两个主题模型的一个角度。如果两个主题在时间趋势上相近,则它们比较可能是想匹配的主题。因此,作者采用了河流(river flow) 的形式来比较两个模型中的主题的时变趋势。如图3所示,上方的河流和下方的河流分别表示了两个模型,每条河流表示一个主题,河流的宽度表示了该主题在这个时间段内的文档数量。我们也可以挑选个别主题进行比较。如图4所示,上方有一个主题,下方则有两个主题,它们的时间趋势较为一致,可能表示上方的一个主题在另一个模型中被拆分成了两个。如果它们的时间趋势如图4(a) 所示,下放的两个主题的时变趋势较为一致,表明这个主题拆分得比较均匀,但另一方面也表明这个拆分可能带有一定的随机性,拆分出的两个主题也许在语义上依然是比较接近的。但若图4(b)所示,下方的两个主题在时间分布上有明显的区分,绿色主题占据了前两个波峰,而紫色主题占据了最后一个波峰。这表明这两个主题可能代表着两个不同的事件,从语义上分析,它们是值得被拆分的。
这篇文章作者主要提出了一种比较不同主题模型方法的可视化工具。作者利用大量的case分别从从主题内容、主题相似性、主题时变这三个不同的角度验证了方法的有效性,对于主题模型而言,其中使用了大量的机器学习和统计方法,对于一般的用户而言很难理解其中的原理,因此自然很难选择最适合自己的方法。通过这套工具,用户能够更好的去理解筛选不同的主题模型,最终选择一个适合自己的模型。
✉️ zjuvis@cad.zju.edu.cn